
How Versal Gen 2 Elevates Edge SDR Performance
In the demanding world of Software Defined Radio (SDR) for aerospace and defense applications, the transition from traditional FPGA-centric designs to heterogeneous adaptive SoCs has been transformative. The AMD Versal Gen 2 AI Edge Series, particularly when integrated into platforms like the SundanceDSP SE2000 3U VPX module with the FMC-ADC500CD daughter card, represents a significant leap forward. This first article in the series examines the architectural evolution from Versal Gen 1 to Gen 2, focusing on how these changes address longstanding bottlenecks in wideband RF sample ingestion, deterministic DSP processing, and real-time orchestration at the tactical edge.
Traditional FPGA-based SDR systems rely heavily on programmable logic (PL) for DSP pipelines. High-speed ADCs interface through JESD204B or similar serial links into the PL fabric, where designers implement FIR filters, DDCs (digital down-converters), FFTs, and beamformers using DSP slices, Block RAM, and UltraRAM. While flexible, this approach frequently encounters routing congestion, difficult timing closure at high clock rates, and synchronization challenges across massive parallel datapaths. For wideband signals, such as those encountered in SIGINT, electronic warfare (EW), or multi-channel radar, the PL fabric can become a bottleneck as sample rates push into giga samples per channel with multiple simultaneous streams.
Versal Gen 1 introduced the AI Engine (AIE) array as a powerful vector processing resource. SDR and DSP developers quickly discovered that these vector engines, originally positioned for AI/ML inference, excelled at complex integer arithmetic (especially cint16), wide SIMD operations, and streaming MAC-heavy workloads. Kernels written in C++ and composed into Adaptive Data Flow (ADF) graphs could offload FIR decimation, polyphase channelizers, and FFT stages with exceptional throughput and power efficiency compared to pure PL implementations. Data movement occurred via PLIO (Programmable Logic IO) interfaces and GMIO (Global Memory IO), routed through the Network-on-Chip (NoC) and cascade streams between tiles.
However, Gen 1 systems still faced limitations. Routing congestion in the PL persisted for high-channel-count designs. ADC sample streams required careful PL buffering and reformatting before reaching AIE arrays, introducing latency jitter and potential stream starvation during bursty wideband captures. Tile memory (typically 32KB SRAM per AIE tile) constrained large FFT buffers or multi-rate filter states, forcing frequent spills to external DDR or complex tiling strategies. The NoC provided high bandwidth but could experience contention without meticulous QoS planning. The processing subsystem (PS), based on Cortex-A72 cores, offered solid application-layer control but lagged in real-time determinism for MAC-layer or waveform-adaptive tasks.
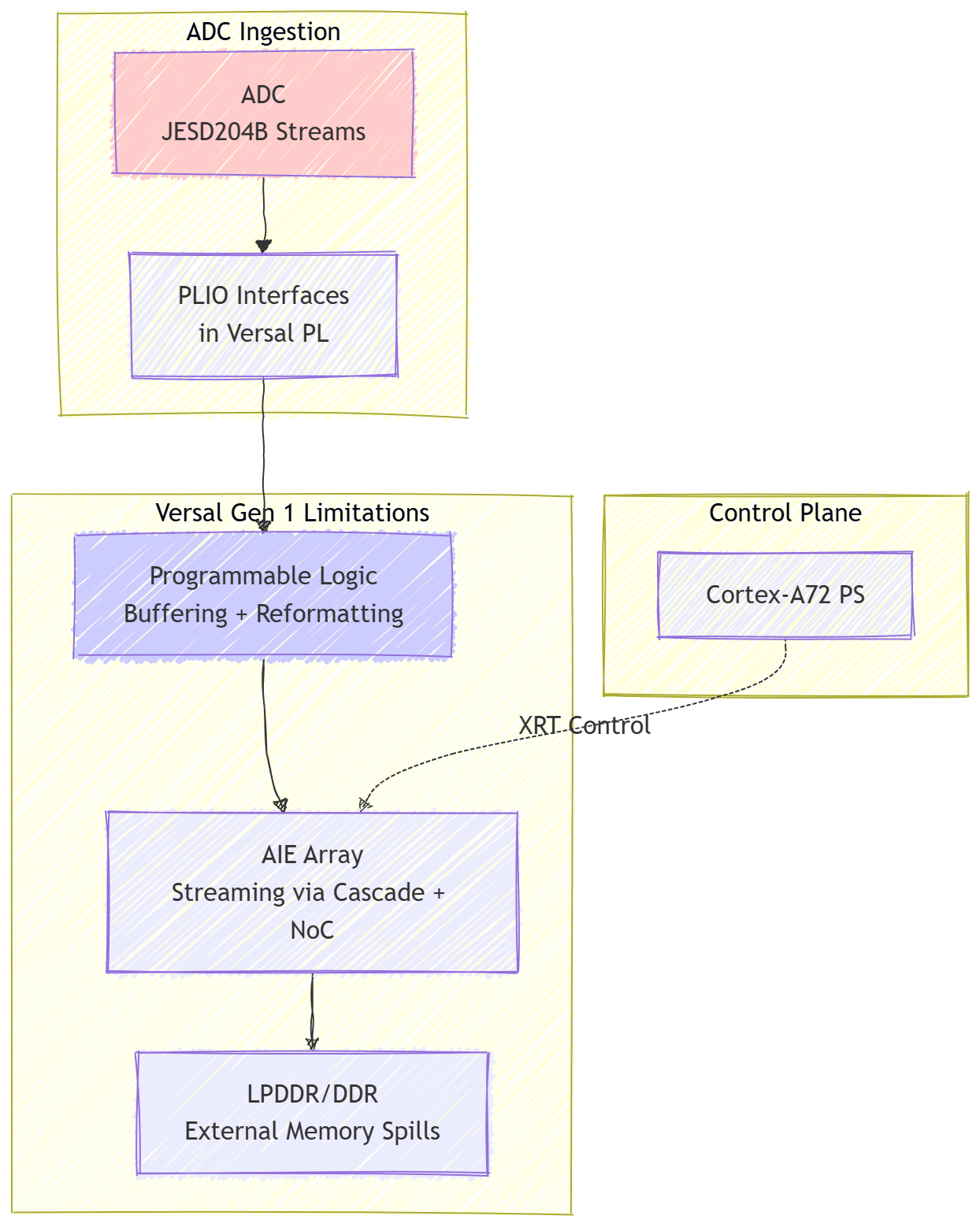
Figure 1: Simplified Gen 1 ADC-to-AIE dataflow, highlighting PL buffering bottlenecks and potential external memory dependencies.
The SundanceDSP SE2000 3U SOSA-aligned OpenVPX module, paired with the FMC-ADC500CD, brings these architectures into rugged deployments. The FMC-ADC500CD (featuring high-speed 1-GSPS ADCs) delivers raw IQ samples directly into the Versal device’s high-pin-count FMC connector. An auxiliary Artix FPGA on the SE2000 handles voltage translation and signal conditioning. Two dual-channel 16-bit streams at 1GSPS generate significant sustained bandwidth, on the order of several GB/s when accounting for overhead, requiring efficient ingestion paths.
Versal Gen 2 fundamentally evolves this architecture. The introduction and refinement of the enhanced programmable Network-on-Chip provides superior bandwidth, lower latency, and better determinism for streaming workloads. Direct data movement from PL into AIE memory boundaries is streamlined, reducing the need for intermediate PL fabric buffering. This is critical for maintaining phase coherence and sample alignment in wideband SDR pipelines. The AIE-ML v2 tiles deliver higher compute density per tile (approximately 2X in many metrics) with improved energy efficiency, while new native data types and enhanced vector datapaths further accelerate cint16 and complex MAC operations common in SDR.
The processing system sees substantial upgrades: Cortex-A78AE application processors replace or augment A72 cores, delivering higher single-thread performance and overall scalar throughput (up to 10X in some generational comparisons for control-plane tasks). The real-time Cortex-R52 subsystem enhances deterministic MAC-layer processing, waveform parameter adaptation, and low-latency control loops. This enables tighter Linux + bare-metal co-existence, where the A78AE cluster handles higher-level protocol stacks and orchestration while R52 cores manage time-critical SDR tasks. LPDDR5X memory interfaces boost external bandwidth, alleviating internal tile SRAM pressure for large spectrum analysis or adaptive filtering buffers.
Consider a typical wideband SDR receive chain on the SE2000:
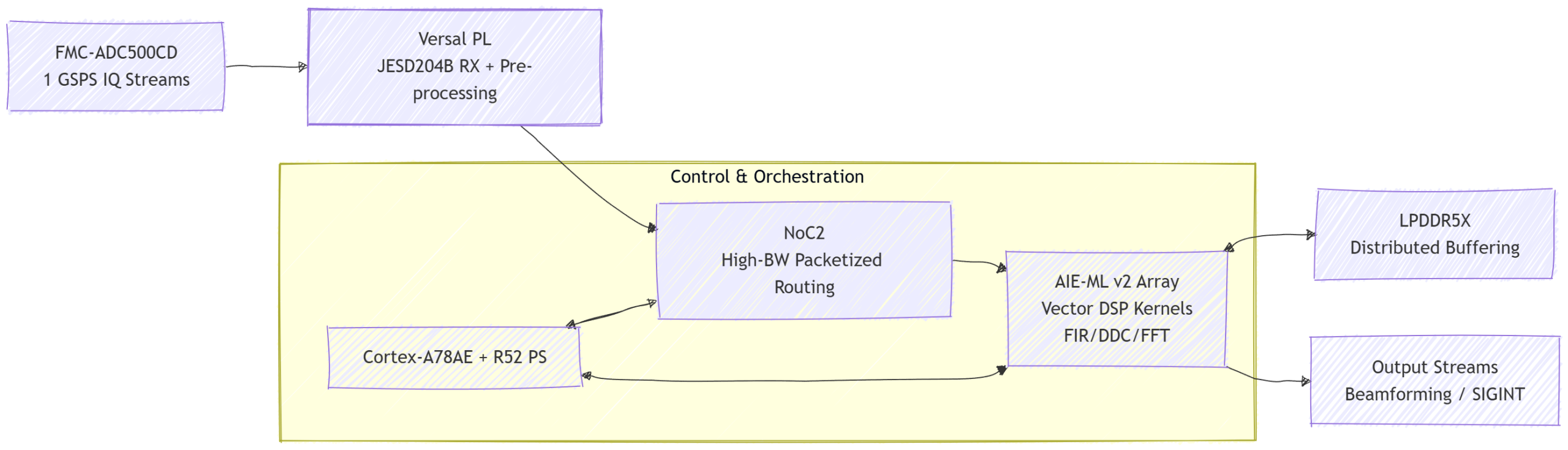
Figure 2: Versal Gen 2 end-to-end streaming architecture on SundanceDSP SE2000. NoC enables direct, deterministic paths from PL to AIE memory, minimizing jitter.
In practice, developers leverage AMD’s AI Engine graph tutorials and PLIO/GMIO examples to map these flows. An ADF graph might define a polyphase channelizer or multi-channel DDC where input windows stream directly from PLIO into AIE tiles via NoC. Packet switching in the NoC supports efficient routing of multi-stream traffic without PL fabric intervention for every sample. This contrasts sharply with traditional FPGA designs, where every interconnect often required manual pipelining and timing closure across the entire fabric.
The result is a more modular hardware/software co-design paradigm. XRT runtime management allows dynamic graph control and partitioning, while the improved scalar engines consolidate Linux-based MAC layers with real-time subsystems. For defense deployments, this means faster adaptation to emerging waveforms, reduced Size, Weight, and Power (SWaP), and better deterministic latency, essential for electronic warfare and radar applications.
Early Versal Gen 1 adopters in SDR communities demonstrated the power of AIE for vector DSP far beyond initial AI marketing. Gen 2 builds on this foundation by resolving ingestion bottlenecks, enhancing internal connectivity, and strengthening the heterogeneous compute hierarchy. On the SundanceDSP SE2000 + FMC-ADC, the combination of high-speed ADC front-ends, robust NoC fabric, dense AIE-ML v2 arrays, and advanced PS creates a platform ready for next-generation edge SDR.
Subsequent articles will dive deeper into the vector engines themselves (Part 2), memory and NoC2 data movement (Part 3), and full deployment/verification workflows (Part 4).