
After years of battling routing congestion, painful timing closure, and excessive fabric resource usage in large UltraScale+ designs, the hardened Network-on-Chip (NoC) in AMD’s Versal platform stands out as a genuine architectural advancement. Instead of building a complex system interconnect entirely from programmable logic resources, Versal introduces a packet-switched, hardened backbone that serves as the primary system-level data movement infrastructure.
The NoC efficiently connects the scalar engines (processing system), adaptable engines (programmable logic fabric), intelligent engines (AI Engine arrays), memory controllers, PCIe subsystems, and other hardened blocks. It manages packetization, QoS-aware arbitration, address-based routing, and clock domain crossing at the NMU/NSU interfaces.
In Versal Gen 2 devices (that are used in SE2000), the NoC has been refined for higher efficiency, improved functional safety, and tighter integration with the second-generation AI Engine array and DDR5 memory controllers.
NoC Topology and System Connectivity in Versal Gen 2
The NoC employs a grid-like topology with horizontal and vertical connectivity paths whose capacity scales with device size and region. NoC Master Units (NMUs) packetize outgoing AXI traffic and inject it into the network, while NoC Slave Units (NSUs) deliver incoming packets to their destinations. The NoC runs in its own clock domain(s), typically in the ~700 MHz to ~1 GHz range depending on the device and speed grade.
Here is a clear conceptual diagram showing how the NoC interconnects the major subsystems in a Versal Gen 2 device:
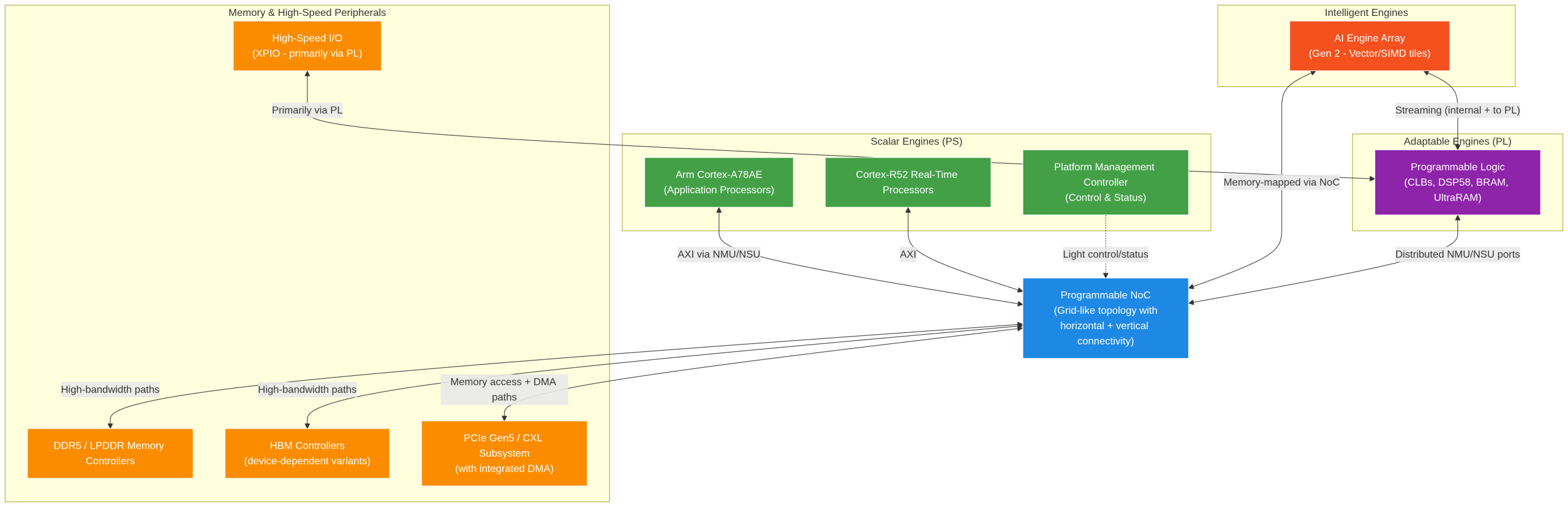
Key Architectural Details
Routing inside the NoC is address-based. The NoC compiler in Vivado uses your traffic specification, including connections, bandwidth targets, and QoS classes (such as isochronous for real-time traffic and best-effort for bulk data), to generate static routing tables and virtual channel assignments. This approach delivers predictable performance and effective traffic isolation.
Clock domain crossing is handled cleanly at the NMU and NSU boundaries, isolating the high-speed NoC domain from user logic clocks in the programmable fabric.
Benefits Compared to Older Xilinx Techniques
In UltraScale+ and Zynq UltraScale+ devices, system interconnects were typically built using soft AXI Interconnect IP or custom fabric switches. In complex designs, these soft implementations could consume 15–40% of logic resources, create heavy routing congestion, make timing closure difficult (especially across SLRs), and increase dynamic power due to constant toggling.
The hardened NoC in Versal Gen 2 provides clear advantages, particularly in complex designs:
- Significant Resource Savings: Many designs recover 30–60% of programmable logic resources previously consumed by soft interconnect logic.
- Higher and More Predictable Bandwidth: The NoC offers tens of GB/s per major interface, with actual throughput depending on configuration, data width, frequency, and QoS settings. DDR5 and HBM traffic benefit substantially from direct hardened connections.
- Built-in QoS Support: Designers can define bandwidth allocations, priorities, and isochronous requirements. The NoC’s QoS-aware arbitration minimizes interference between traffic classes far more effectively than custom fabric arbiters.
- Simplified Timing Closure: High-speed paths are confined to hardened silicon. The programmable logic only needs to close timing to local NMU/NSU interfaces, which greatly eases floorplanning and supports Dynamic Function eXchange (DFX).
- Better Power Efficiency: Significant power savings are achieved versus equivalent soft implementations due to lower capacitance and reduced unnecessary fabric activity.
What the NoC Is Not
It is important to set realistic expectations. The NoC is not a fully dynamic, runtime-reconfigurable network like some academic NoCs; routing and QoS are largely fixed at compile time. It is also not the best solution for every connection; very low-latency, localized streaming inside the PL is often better kept in fabric logic. While it greatly improves predictability, it does not eliminate latency.
Practical Takeaways
Success with Versal Gen 2 starts with early engagement with the NoC. Define your major traffic flows, set realistic bandwidth and QoS targets in the NoC compiler, and let the hardened infrastructure handle system-level communication. The payoff appears in higher fabric utilization, cleaner timing reports, lower power consumption, and faster development cycles, especially in demanding applications such as real-time AI inference, 5G/radar processing, and automotive sensor fusion.
After fighting soft interconnect limitations for years on older Xilinx parts, the NoC in Versal Gen 2 feels like proper infrastructure. It quietly does the heavy lifting, allowing engineers to focus on actual acceleration rather than data movement plumbing.