
Examining the Core Vector Engines
The true power of the AMD Versal architecture for Software Defined Radio (SDR) and Digital Signal Processing (DSP) lies not solely in the programmable logic or the processing subsystem, but in the array of specialized vector processors known as AI Engines. While initially marketed toward machine learning inference, SDR and radar engineers rapidly adopted Versal Gen 1 AI Engines as extraordinarily efficient vector DSP accelerators. The Versal Gen 2 AIE-ML v2 tiles take this capability to a new level, delivering dramatically higher MAC density, improved energy efficiency, and enhanced support for the complex fixed-point arithmetic that dominates wideband SDR workloads.
In traditional FPGA-only DSP pipelines on platforms like the SundanceDSP SE2000, engineers map filters, FFTs, and beamformers onto DSP slices and fabric resources. This approach offers fine-grained control but incurs high routing overhead, challenging timing closure at multi-hundred-MHz clocks and leading to significant power consumption for sustained high-throughput operations. Data movement between pipeline stages often requires explicit handshaking and deep FIFOs, leading to synchronization complexity in multi-channel or multi-rate systems fed by the FMC-ADC500CD’s dual (or quad) high-speed ADC streams.
Versal Gen 1 introduced the original AI Engine (AIE) and AIE-ML tiles. Each tile featured a VLIW vector processor with 512-bit vector registers, supporting wide SIMD operations including native cint16 (complex 16-bit integer) arithmetic. A single complex MAC operation could be issued efficiently, with dedicated hardware for multiply-accumulate on complex data. Tile-local SRAM (typically 32 KB for AIE, more in AIE-ML) served as fast window buffers for streaming data. Kernels communicate via 32-bit or 64-bit stream interfaces, with cascade streams allowing direct tile-to-tile accumulation of partial results, ideal for long FIR filters or large FFTs.
SDR developers embraced this because a well-written AIE kernel could sustain multiple hundred MSPS of cint16 processing with deterministic behavior and far lower power than equivalent PL fabric implementations. Adaptive Data Flow (ADF) graphs allowed the composition of kernels (FIR → DDC → FFT → beamformer) with automated stream routing. AMD Vitis DSP Library examples for FIR (single-rate, half-band, interpolation/decimation) and FFT (DIT 1-channel) provided production-ready starting points that mapped directly to polyphase channelizers and spectrum analysis pipelines common in SIGINT and EW.
However, Gen 1 had constraints. Limited per-tile memory pressured large FFT twiddle tables or multi-tap filter states. Cascade streams were primarily horizontal with limited vertical support, constraining certain 2D or matrix-oriented beamforming layouts. Vector datapath efficiency, while excellent for cint16, left headroom for further optimization in multi-rate and mixed-precision scenarios.
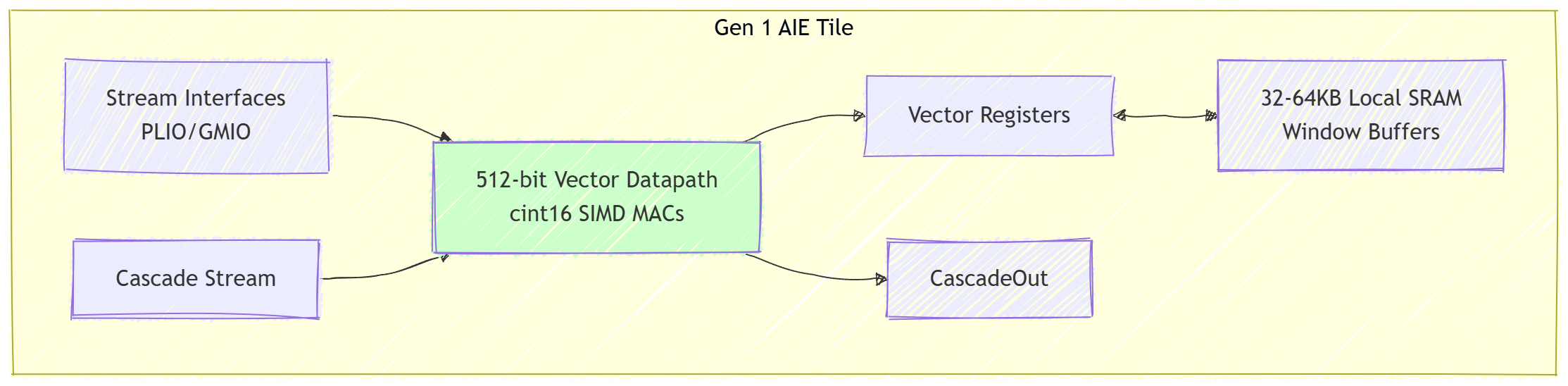
Figure 1: High-level architecture of a Gen 1 AI Engine tile, optimized for streaming vector DSP with local memory and cascade support.
Versal Gen 2 introduces the AIE-ML v2 architecture, delivering approximately 2X compute per tile compared to previous-generation AIE-ML, with up to 3X better TOPS/W in relevant datatypes. New native support for additional formats (including enhanced handling of FP16/FP8 and micro-scaling MX6/MX9 in some configurations) complements the core cint16 and int16 strengths critical for SDR. The vector unit maintains and expands the 512-bit (or wider effective) SIMD capability, with improved instruction scheduling and higher MAC density for complex arithmetic.
In AIE-ML v2, the datapath excels at complex MAC operations. A single instruction can perform multiple parallel cint16 multiplies and accumulates, leveraging the VLIW nature to overlap scalar control, address generation, and vector execution. This is particularly powerful for FIR implementations: a symmetric FIR kernel from the Vitis DSP Library can process multiple output samples per cycle with minimal stalls when data is properly windowed into local SRAM. For the FMC-ADC500CD streams (1 GSPS per channel, 16-bit IQ), this means the AIE array can ingest and channelize wideband data with headroom for adaptive filtering or pulse compression.
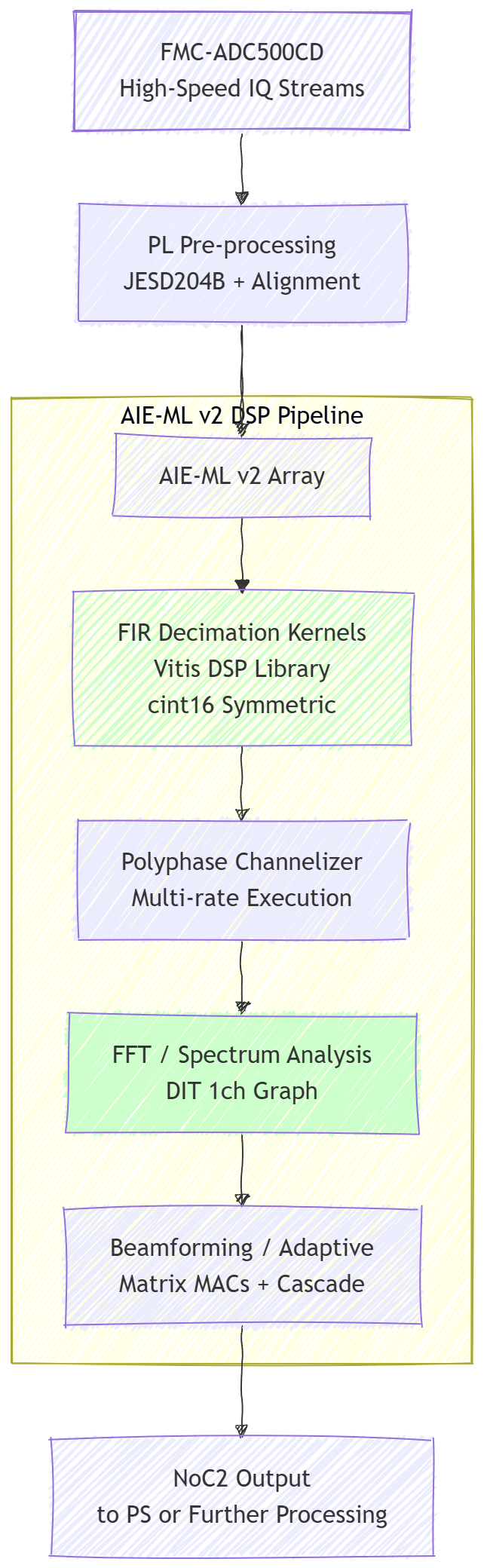
Figure 2: Typical SDR receive chain mapped to AIE-ML v2 tiles on the SundanceDSP SE2000. Vector engines decouple compute-intensive math from PL fabric routing.
Tile memory interaction is significantly enhanced. Larger local SRAM per tile (often doubled in effective capacity for AIE-ML v2) reduces stream starvation and allows bigger window sizes for overlap-save FFT or long polyphase filters. Improved memory banking minimizes conflicts during simultaneous stream ingress, vector access, and cascade operations. Cascade streams in Gen 2 support better connectivity (including enhanced vertical options), enabling more flexible systolic-like arrays for digital beamforming across hundreds of antenna elements.
Consider a multi-channel DDC or beamforming application. In a PL-only design, each channel might consume dozens of DSP slices with complex pipelining. On Gen 1 AIE, a single kernel or small graph could handle multiple channels via time-division or SSR (super-sample rate) techniques. With AIE-ML v2, higher per-tile throughput and better efficiency allow consolidation of more channels per tile or higher sample rates, directly benefiting the SE2000’s high-bandwidth ADC ingestion in rugged 3U VPX environments.
The Vitis DSP Library provides concrete examples: fir_sr_sym_graph for symmetric FIRs, fft_ifft_dit_1ch_graph for FFTs, and matrix-oriented kernels for beamforming weight application. These can be instantiated in ADF graphs, with runtime parameters adjusted via the XRT interface for adaptive waveforms. Developers report that SDR pipelines achieve deterministic latency critical for phased-array radar and electronic warfare, where phase continuity across processing stages must be preserved.
Compared to traditional FPGA DSP chains, AIE vector processing decouples the vector math from the interconnect fabric. Kernels operate at a higher abstraction with stream-based dataflow, while the enhanced NoC (detailed in Part 3) handles routing. This yields superior power efficiency and scalability. Gen 2’s improvements, higher MAC density, better memory hierarchy, and optimized arithmetic pipelines make it dramatically superior for sustained wideband workloads like OFDM processing, MIMO, or real-time spectrum monitoring.
On the SundanceDSP SE2000, the combination of FMC-ADC500CD raw sample streams into the PL, efficient handoff via NoC to the AIE-ML v2 array, and local vector execution creates a highly capable edge SDR platform. Engineers can focus on algorithmic DSP kernels rather than low-level timing closure, accelerating development of next-generation tactical systems.
This vector engine evolution is foundational. The next article explores how NoC and the distributed memory matrix solve the data starvation problems that often limit sustained performance in these high-throughput pipelines.