
Enhanced NoC and the Distributed Memory Matrix
In high-performance SDR and DSP systems, raw vector compute capability is necessary but insufficient. Sustained performance is overwhelmingly gated by memory bandwidth, on-chip data movement, and the ability to keep compute tiles fed without introducing jitter or breaking phase continuity. This is especially true on the Sundance SE2000 3U VPX module paired with the FMC-ADC500CD, where two dual-channel 16-bit 1 GSPS IQ streams can deliver multi-GB/s of continuous sample data that must be channelized, filtered, beamformed, and analyzed in real time. Versal Gen 2’s NoC and expanded distributed memory architecture directly address the data starvation and routing limitations that constrained Gen 1 deployments and continue to plague traditional FPGA DSP pipelines.
Traditional FPGA designs handle high-speed ADC data by bringing JESD204B streams into the PL fabric, where designers build deep FIFO structures, wide bus multiplexers, and carefully pipelined interconnects. For wideband multi-channel applications, this leads to massive routing congestion, difficult timing closure, and synchronization headaches when aligning samples across channels or maintaining phase relationships for beamforming and pulse compression. External DDR access adds variable latency, while on-chip BRAM/UltraRAM resources become fragmented and contended.
Versal Gen 1 improved the situation by allowing AI Engine arrays to pull data via PLIO and GMIO interfaces through the NoC. However, limitations remained pronounced. Individual AIE tiles relied on relatively small local SRAM (32 KB), forcing frequent window management for overlap-save FFTs, long polyphase filters, or multi-tap adaptive equalizers. Large FFT buffers or radar range-Doppler maps often spilled to external memory, introducing NoC contention and variable latency. Stream starvation occurred during bursty wideband captures or when multi-kernel graphs competed for shared routing resources. Cascade streams helped local systolic flow but did not solve global data distribution challenges. Memory banking conflicts and NoC hotspotting degraded determinism, unacceptable for tactical edge SIGINT, EW, or phased-array radar.
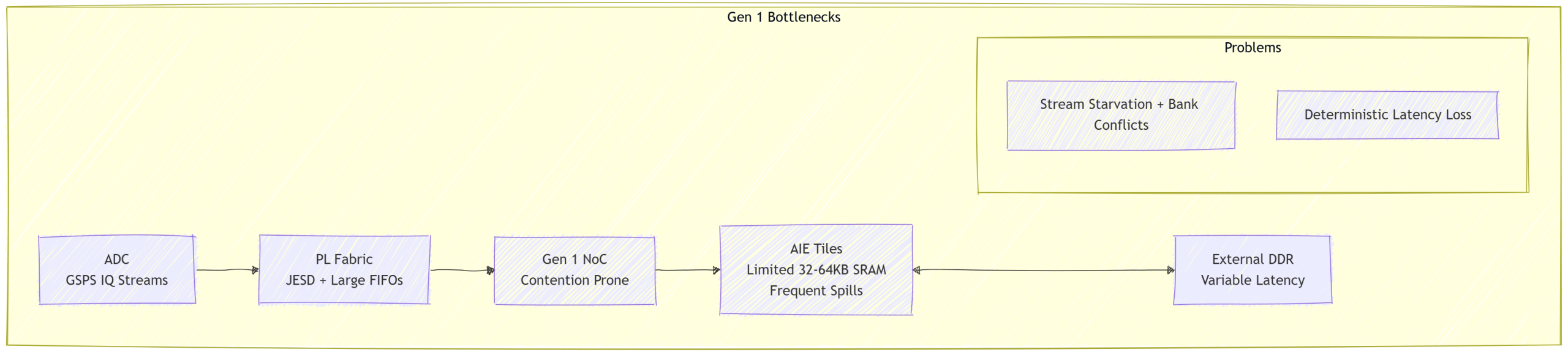
Figure 1: Data starvation pathways in Gen 1 architectures. High-rate streams from the ADC overwhelm limited tile memory and shared NoC resources.
Versal Gen 2 introduces Enhanced NoC, a significantly enhanced programmable Network-on-Chip with higher aggregate bandwidth, improved QoS mechanisms, lower and more predictable latency, and superior packet switching capabilities. New NoC supports more direct paths from PL interfaces into AIE memory boundaries, reducing intermediate buffering requirements. This enables raw ADC samples (after minimal PL JESD204B termination and alignment) to flow efficiently into the AI Engine array with tight control over routing and scheduling.
Complementing NoC is an expanded distributed memory matrix. Gen 2 includes additional memory tiles (larger and more numerous in the AI Edge variants), providing a shared but locally accessible pool that AIE tiles can access with lower latency than external LPDDR5X while offering far greater capacity than local tile SRAM. LPDDR5X interfaces deliver substantially higher external bandwidth with improved power efficiency, serving as a high-capacity backing store for spectrum snapshots, deep filter histories, or large beamforming weight matrices without crippling real-time pipelines.
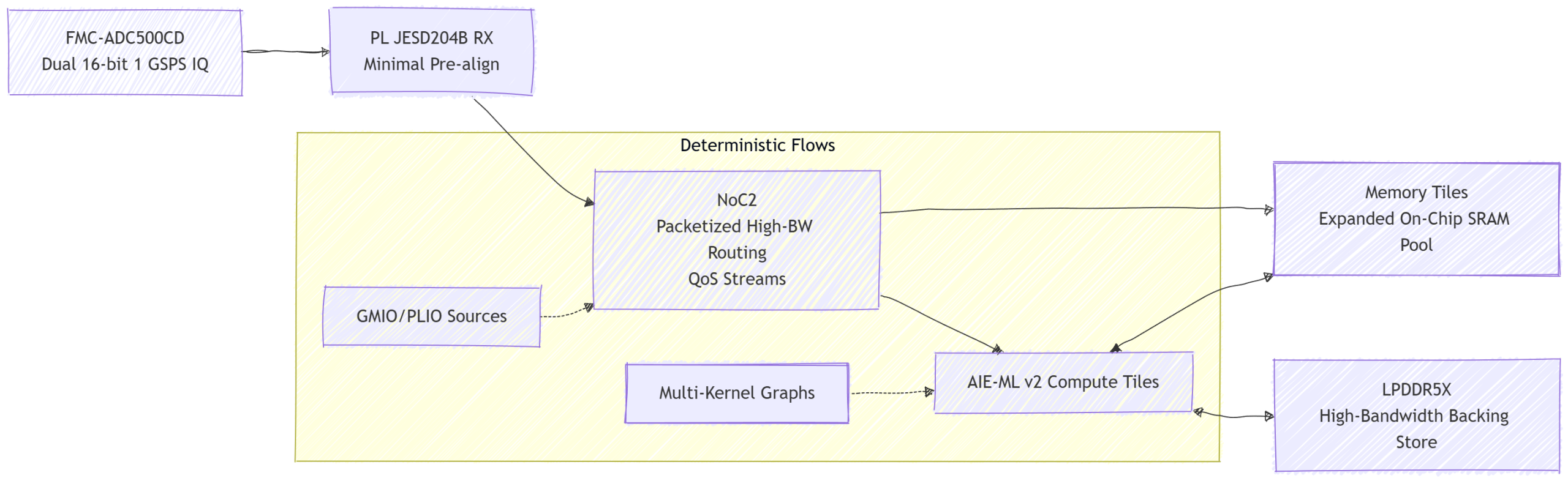
Figure 2: Gen 2 NoC2-centric data movement on the Sundance SE2000. Packetized routing and memory tiles eliminate classic starvation while preserving phase coherence.
In practice, AMD’s GMIO and packet switching examples demonstrate how to configure multiple high-priority streams from the FMC front-end through NoC2 directly into AIE tile windows or memory tiles. Multi-kernel streaming graphs—such as parallel polyphase channelizers feeding a shared FFT engine benefit from NoC’s improved scheduling, which minimizes head-of-line blocking and bank conflicts. Developers use memory tile tutorials to stage large FFT input buffers or overlap-save windows on-chip, then stream results tile-to-tile via enhanced cascade streams or NoC for subsequent vector processing (e.g., beamforming matrix multiplies or adaptive filtering).
Deterministic data movement is a game-changer for SDR. NoC’s predictable latency and reduced jitter ensure phase continuity across long DSP chains, critical when processing OFDM symbols, maintaining coherence in MIMO systems, or performing digital beamforming where sub-sample alignment directly impacts null depth and gain. On the SE2000 platform, this means the high-speed ADC streams can be ingested, channelized, and forwarded to downstream processing (or external VPX backplane) with reliable timing that traditional FPGA synchronization primitives struggle to match at scale.
Stream scheduling in the ADF graph compiler, combined with runtime XRT controls, allows engineers to define QoS priorities and explicit routing constraints. This contrasts with Gen 1, where manual intervention and simulation iteration were often required to resolve contention. Bank conflict reduction in the distributed memory matrix further sustains high utilization of the AIE-ML v2 vector datapaths, keeping cint16 MAC engines busy even under full wideband load from the FMC-ADC500CD.
Real-world mapping using AMD Vitis Acceleration and AI Engine examples includes:
- GMIO-based high-rate input ports feed packetized sample blocks into memory tiles.
- Multi-kernel graphs with cascaded FIR → DDC → FFT stages where intermediate results flow through NoC without PL intervention.
- Data mover kernels that efficiently transfer large blocks between LPDDR5X and on-chip memory tiles for radar pulse compression or SIGINT recording.
These capabilities allow the SundanceDSP SE2000 to maintain real-time SDR buffering and processing without the classic FPGA problems of metastability domains, clock domain crossing penalties, or massive resource overhead for FIFOs. The result is higher sustained throughput, lower deterministic latency, and better overall system reliability in aerospace and defense deployments.
By solving data starvation at the architectural level, Versal Gen 2 shifts the design focus from fighting bandwidth bottlenecks to optimizing algorithmic performance and waveform agility. The AIE-ML v2 vector engines (Part 2) can now operate near peak efficiency, fed by a robust NoC and memory hierarchy that scales with the demanding requirements of tactical edge compute.
The final article in this series will address model-to-mission workflows: runtime orchestration, verification, simulation, and field deployment on SE2000.